LoFT: Low-Rank Adaptation That Behaves Like Full Fine-Tuning
Large pre-trained models are commonly adapted to downstream tasks using parameter-efficient fine-tuning methods such as Low-Rank Adaptation (LoRA), which injects small trainable low-rank matrices instead of updating all weights. While LoRA dramatically reduces trainable parameters with little overhead, it can still underperform full fine-tuning in accuracy and often converges more slowly. We introduce LoFT, a novel low-rank adaptation method that behaves like full fine-tuning by aligning the optimizer’s internal dynamics with those of updating all model weights. LoFT not only learns weight updates in a low-rank subspace (like LoRA) but also properly projects the optimizer’s first and second moments (Adam’s momentum and variance) into the same subspace, mirroring full-model updates. By aligning the low-rank update itself with the full update, LoFT eliminates the need for tuning extra hyperparameters, e.g., LoRA scaling factor $\alpha$. Empirically, this approach substantially narrows the performance gap between adapter-based tuning and full fine-tuning and consistently outperforms standard LoRA-style methods, all without increasing inference cost.
Authors: N. Tastan, Stefanos Laskaridis, M. Takac, K. Nandakumar, S. Horvàth
Published at: International Conference on Learning Representations (ICLR’26)
Overview
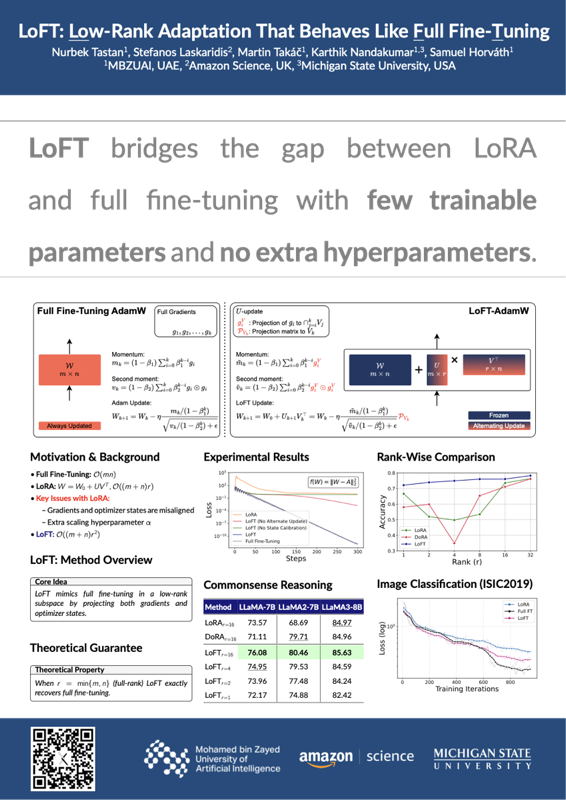
The LoFT framework advances parameter-efficient model adaptation by addressing key limitations of traditional low-rank methods such as LoRA, which often underperform full fine-tuning due to misaligned optimizer dynamics and sensitivity to hyperparameters. LoFT introduces a novel optimizer that not only learns low-rank weight updates but also projects the optimizer’s first and second moments (e.g., Adam’s momentum and variance) into the same low-rank subspace, closely mirroring the behavior of full-model updates; this alignment eliminates the need for extra scaling hyperparameters and substantially narrows the performance gap with full fine-tuning, resulting in more robust and accurate adaptation without increasing inference cost.
Links
Reference
@inproceedings{
tastan2026loft,
title={LoFT: Low-Rank Adaptation That Behaves Like Full Fine-Tuning},
author={Tastan, N. and Laskaridis, Stefanos and Takac, M. and Nandakumar, K. and Horvàth, S.},
booktitle={International Conference on Learning Representations},
year={2026}
}
